
[ad_1]
That’s the query posed in paper by Baker, Larcker and Wang (2022). I summarize their key arguments beneath.
The validity of…[the DiD]…method rests on the central assumption that the noticed pattern in management models’ outcomes mimic the pattern in remedy models’ outcomes had they not obtained remedy. Because the authors write:
First, DiD estimates are unbiased in settings with a single remedy interval, even when there are dynamic remedy results. Second, DiD estimates are additionally unbiased in settings with staggered timing of remedy project and homogeneous remedy impact throughout companies and over time. Lastly, when analysis settings mix staggered timing of remedy results and remedy impact heterogeneity, staggered DiD estimates are probably biased.
Oftentimes, DiD is carried out utilizing an abnormal least squares (OLS) regression based mostly mannequin as follows:
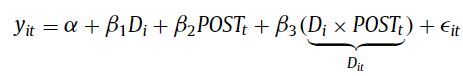
When there are greater than two teams and greater than and a couple of time intervals, regression-based DiD fashions sometimes depend on two-way mounted impact (TWFE) of the shape:
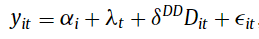
The place the primary two coefficients are unit and time interval
mounted results. Observe that earlier analysis from Goodman-Bacon
(2021) exhibits that static types of the TWFE DiD is definitely a “weighted
common of all attainable two-group/two-period DiD estimators within the information.”
When remedy results can change over time (“dynamic
remedy results”), staggered DiD remedy impact estimates can really
receive the other signal of the true ATT, even when the researcher have been in a position to
randomize remedy project (thus the place the parallel-trends assumption
holds).
The explanation for it is because Goodman-Bacon
(2021) exhibits that the static TWFE DiD is definitely consists of three elements:
- Variance-weighted common remedy impact on
the handled (VWATT) - Variance-weighted common counterfactual tendencies
(VWCT) - Weighted sum of the change within the common
remedy on the handled inside a treatment-timing group’s post-period and
round a later-treated unit’s remedy window (ΔATT)
The primary time period is the time period of curiosity. If the parallel tendencies happens, then VWCT =0. The final time period arises as a result of, underneath static
TWFE DiD, already-treated teams as successfully used as comparability teams for later-treated
teams. If DiD is estimated in a
two-period mannequin, nonetheless, this time period disappears and there’s no bias. Alternatively,
if remedy results are static (i.e., not altering over time after the
intervention), then ΔATT = 0 and TWFE DiD is legitimate.
The challenges, nonetheless, happens when remedy results are
dynamic. On this case ΔATT
≠
0 and the TWFE DiD is biased.
So what could be executed? The authors provide 3 options:
- Callaway and Santa’Anna (2021). Right here, the authors permit one to estimate remedy impact for a selected group (remedy at time g) utilizing observations at time τ and g-1 from a clear set of controls. These are principally not-yet handled, last-treated, or never-treated teams.
- Solar and Abraham (2021). The same methodology is used as in CS, however always-treated models are dropped, and the one models that can be utilized as efficient controls are these which are never-treated or last-treated. Additional, this method is absolutely parametric.
- Stacked regression estimators. Cengiz (2019) implements this method. The purpose is to “create event-specific “clear 2 × 2” datasets, together with the result variable and controls for the handled cohort and all different observations which are “clear” controls inside the remedy window (e.g., not-yet-, last-, or never-treated models). For every clear 2 × 2 dataset, the researcher generates a dataset-specific figuring out variable. These event-specific information units are then stacked collectively, and a TWFE DiD regression is estimated on the stacked dataset, with dataset-specific unit- and time-fixed results… In essence, the stacked regression estimates the DiD from every of the clear 2 × 2 datasets, then applies variance weighting to mix the remedy results throughout cohorts effectively.”
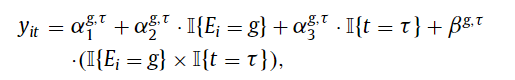
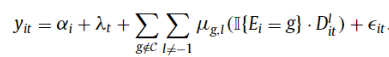
Whereas there was lots of math on this submit, if researchers apply these different DiD estimators, the authors correctly suggest that “researchers ought to justify their selection of ‘clear’ comparability teams—not-yet handled, final handled, or by no means handled—and articulate why the parallel-trends assumption is prone to apply”.
You may learn the total article right here.
[ad_2]